
Le Système national des données de santé (SNDS) : une base de données taillée pour l’intelligence artificielle
Dans le contexte actuel, les données cliniques, de registres et du SNDS sont au centre de l’attention. Et pour cause, ces bases contiennent la quasi-totalité des parcours de soins de l’ensemble de la population française. Elle regorge par conséquent d’une grande quantité d’informations, qu’il faut savoir trier et analyser pour en extraire une utilité de santé publique.
Par ailleurs, les innovations liées à l’Intelligence Artificielle sont d’une aide précieuse dans l’exploitation des grandes bases de données. En effet, elles permettent de gérer à la fois les volumes gigantesques, et la complexité des relations entre ces données. En santé, l’IA est surtout connue pour l’essor des opérations chirurgicales assistées par robot, pour l’analyse d’images automatisées ou encore pour les prothèses connectées.
C’est sur un autre axe, celui de l’analyse des données de santé, que la petite sœur de l’IA, connue sous le nom de Machine Learning, nous aide au quotidien. Le Machine Learning n’est rien de plus qu’une boîte à outils : elle contient des algorithmes, qui sont à disposition de l’analyste. Chaque outil doit être minutieusement choisi, puis paramétré sur mesure pour répondre à la problématique rencontrée. Ce choix et ce paramétrage sont le quotidien du métier de data scientist.
Le TAK : une IA en réponse à un besoin réel
Chez HEVA, nous avons observé que nous étions régulièrement confrontés aux questions suivantes :
- Combien de temps les patients sont-ils traités ?
- Par quelles séquences de traitements ?
- Où sont les switchs de médicaments et les arrêts de traitements ?
- Les recommandations des stratégies thérapeutiques sont-elles suivies ?
Ceci nous a amené à formuler la problématique suivante : comment pourrions-nous représenter l’enchaînement des traitements chez les patients d’une cohorte, et ce sur plusieurs années ?
Cette problématique fut le point de départ du développement de la technique du TAK (Time-sequence Analysis through K-clustering). La difficulté majeure que surmonte la technique d’IA TAK est de concilier à la fois (a) une représentation exhaustive de la cohorte, (b) une vision temporelle précise, et (c) en fournissant un résultat lisible.
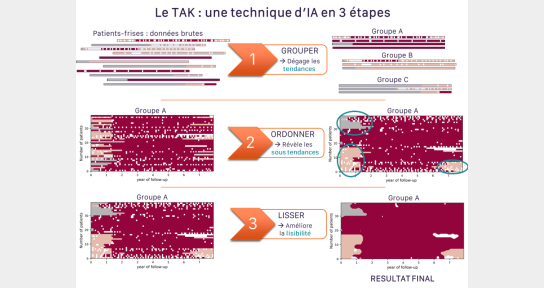
Figure 1. Le TAK : une technique d’IA en 3 étapes
(1) Chaque patient est représenté comme une frise chronologique sur laquelle chaque couleur correspond à une phase de traitement (la prise d’un médicament, une pause thérapeutique, etc.) [en haut à gauche]. La première étape intelligente du TAK rassemble ces frises-patients en groupes, selon leur similarité [en haut à droite].
(2) Dans chacun des groupes, un second outil est utilisé : les frises sont placées les unes au-dessus des autres [milieu à gauche], ordonnées de manière à faciliter la lecture [milieu à droite]. Les étapes (1) et (2) sont réalisées à l’aide de l’outil « Hierarchical Agglomerative Clustering », une technique de Machine Learning non supervisée.
(3) La dernière étape est piochée dans les outils d’image processing : un flou est appliqué sur chacun des groupes, pour faire disparaitre les atypies de l’image finale, et rendre la lecture plus claire et agréable.
Plus concrètement, le TAK a été utilisé par exemple pour décrire les séquences de traitements des 3 400 patients incidents atteints du VIH en 2013. Il a aidé à consolider la définition de la population en mettant en évidence un millier de patients dont les traitements mettaient en doute leur appartenance à la cohorte. Par sa résistance aux atypies, il donne une vision d’ensemble lisible des traitements délivrés les 2 premières années de suivi de ces patients. Nous avons pu également observer, avec une notion précise de temporalité, les patients n’ayant pas été traités tout au long de leur suivi.
Plus généralement, l’association des données du SNDS et de plusieurs techniques d’intelligence artificielle telles que le TAK a permis d’observer l’effet de pénuries, la pénétration d’un médicament dans l’arsenal thérapeutique ou encore les déviations aux recommandations officielles. Il est également possible d’intégrer d’autres informations des patients dans l’équation, afin de repérer des différences de parcours en fonction de l’âge ou du sexe, ou de variables plus fortement liées à la maladie étudiée (rechute, stade de la maladie).
Loin de l’imaginaire d’une « baguette magique », le Machine Learning nous aide ici à visualiser l’entièreté d’une cohorte de patients et à comprendre leurs enchainements de traitements malgré leur complexité. Toutefois, les outils ne fonctionneront jamais sans l’aide de l’expertise métier des médecins spécialistes de la maladie étudiée et des spécialistes de la donnée. C’est en travaillant ensemble, chacun apportant ses propres compétences, que nous arriverons à tirer le grand potentiel de ces données de santé.


